

🚀 The incorporation of the HNSW index in pgvector v0.5.0 ensures lightning-fast vector searches. We tested it, benchmarked it, and shared everything. Read the new post
There are a few pgvector benchmarks floating around the internet, most recently a pgvector vs Qdrant comparison by NirantK. We wanted to reproduce (or improve!) the results.
There is an obvious bias here: we're a Postgres company. It's not our goal to prove that pgvector is better than Qdrant for running vector workloads. From everything we hear about Qdrant, it's fantastic.
Our goals in this article are:
- To show the strengths and limitations of the current version of pgvector.
- Highlight some improvements that are coming to pgvector.
- Prove to you that it's completely viable for production workloads and give you some tips on using it at scale. We'll show you how to run 1 million Open AI embeddings at ~1800 queries per second with 91% accuracy, or 670 queries per second with 98% accuracy.
Benchmark Methodology
We've used the ANN Benchmarks methodology, a standard for benchmarking vector databases.
The key elements are:
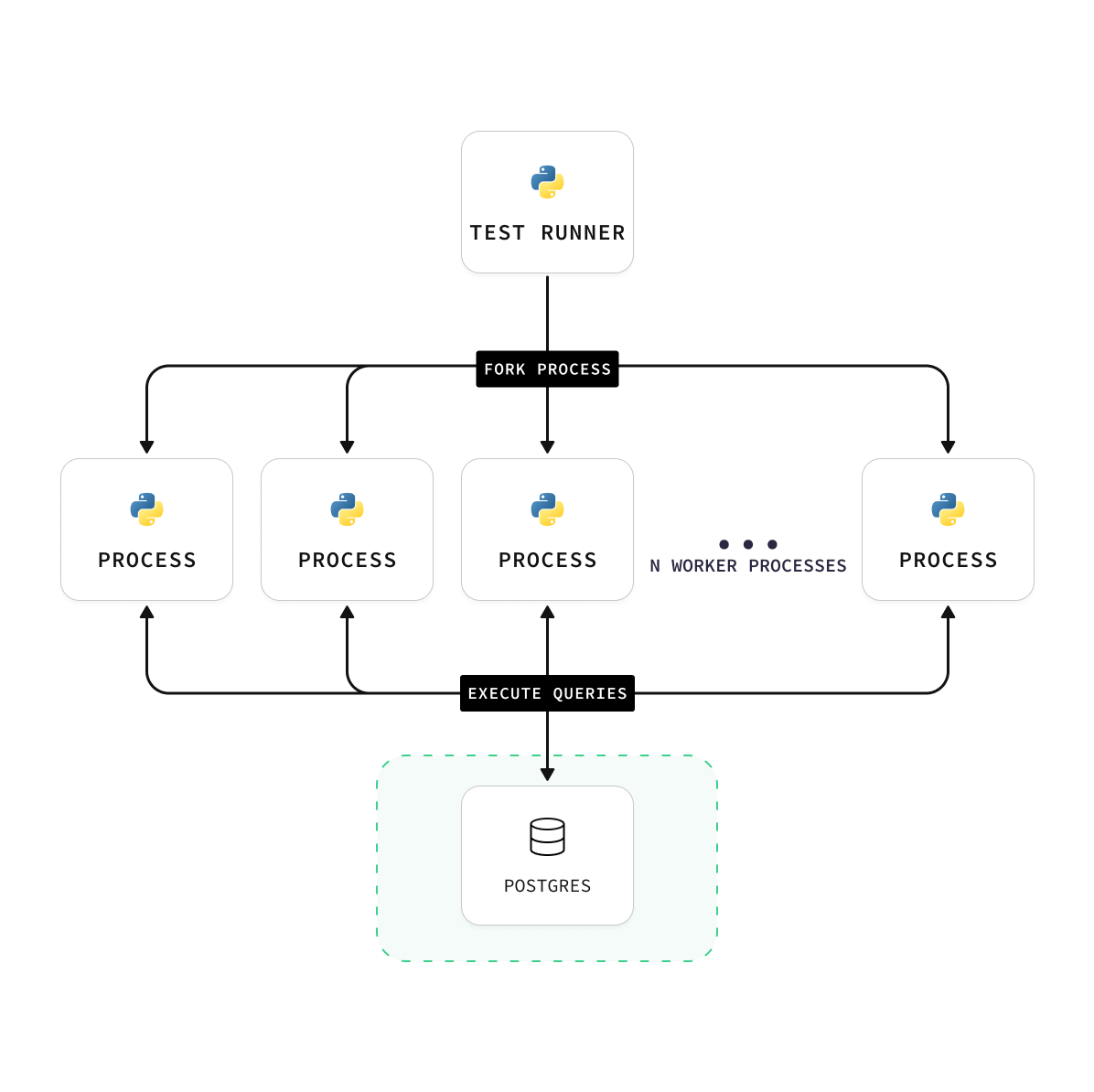
- Helper scripts: a Python test runner which is responsible for data upload, index creation, and query execution. This uses qdrant's vector-db-benchmark repo. The “engine” in this repo uses Vecs, a Python client for pgvector.
- Runtime: Each test runs for at least 30-40 minutes and includes a series of experiments executed at various concurrency levels. This process allowed us to gauge the engine's performance under different load types. Subsequently, we averaged the results.
- Pre-warming RAM: We executed 10,000 to 50,000 “warm-up” queries before each benchmark, matching the number of probes as the benchmark. Additionally, we executed about 1,000 queries with probes ranging from three to ten times the benchmark's probes. Both of these help with RAM utilization.
Hardware
All compute add-ons available on Supabase were used to run our benchmarks. Each add-on variant has a different allocation of RAM and CPU cores, the details of which are available in our docs. Each Supabase compute add-on comes with a specific set of optimizations (version 2023-07).
| Instance | CPU | Memory |
|---|---|---|
| 2XL | 8-core ARM (dedicated) | 32 GB |
| 4XL | 16-core ARM (dedicated) | 64 GB |
| 8XL | 32-core ARM (dedicated) | 128 GB |
| 12XL | 48-core ARM (dedicated) | 192 GB |
| 16XL | 64-core ARM (dedicated) | 256 GB |
Dataset
We tested using the same dataset as the Qdrant comparison: dbpedia-entities-openai-1M. This dataset includes 1M embeddings with 1536 dimensions (created using OpenAI). The embeddings are created by Wikipedia articles. It's a great dataset!
We also have some useful benchmarks in our docs for gist-960-angular (1M image embeddings, 960 dimensions) and GloVe Reddit comments (1.6M text embeddings, 512 dimensions).
Baseline
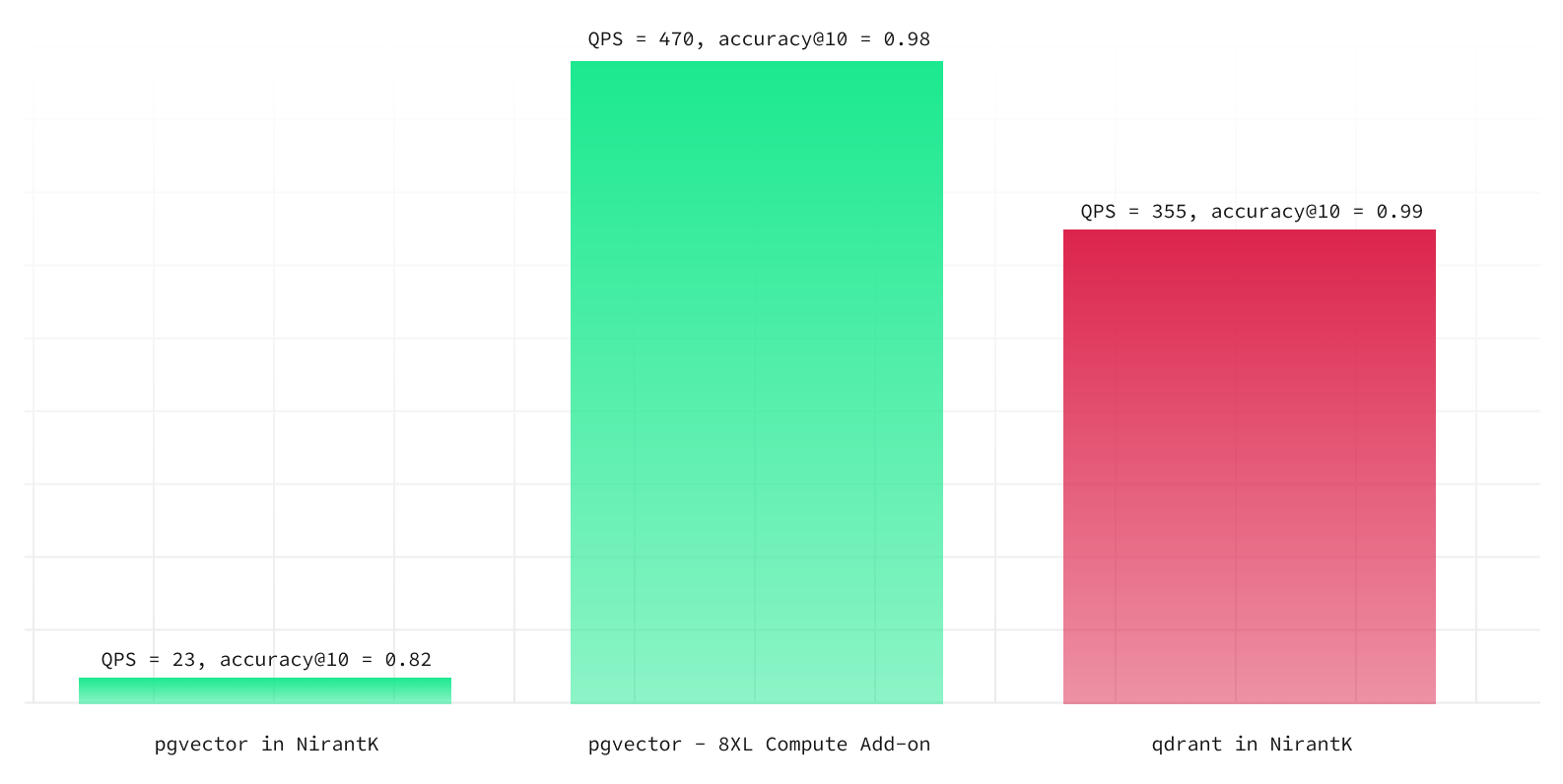
Let's start with NirantK's results as a baseline:
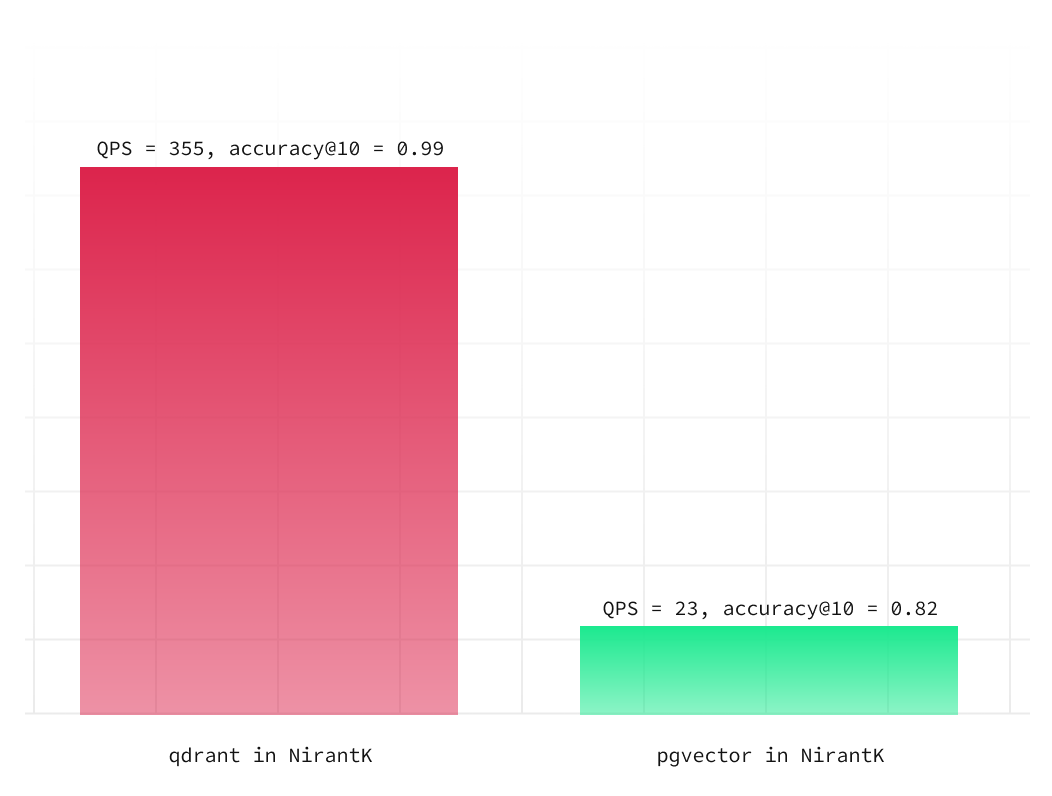
They aren't very flattering! Repeating our statements above, these benchmarks use the defaults for both engines. Our goal now is to replicate the results, and then see what improvements need to be made as developers scale up their workload.
Results
Our tests mirrored NirantK's: but incorporated slight variations:
Same:
- We used the same dataset
- We used the same hardware: a 2XL instance on Supabase, which offers the same core and RAM count as NirantK's machine - 8 cores and 32 GB of RAM
Changed:
- We used the pre-warming technique described earlier.
- We used the
inner-productdistance function. - We set
listsconstant for an index equal to 2000 instead of 1000. - We adjusted the Probes in various runs to benchmark the difference (NirantK's tests used
probes = 1).
The resulting figures were significantly different after these changes.
PROBES = 10
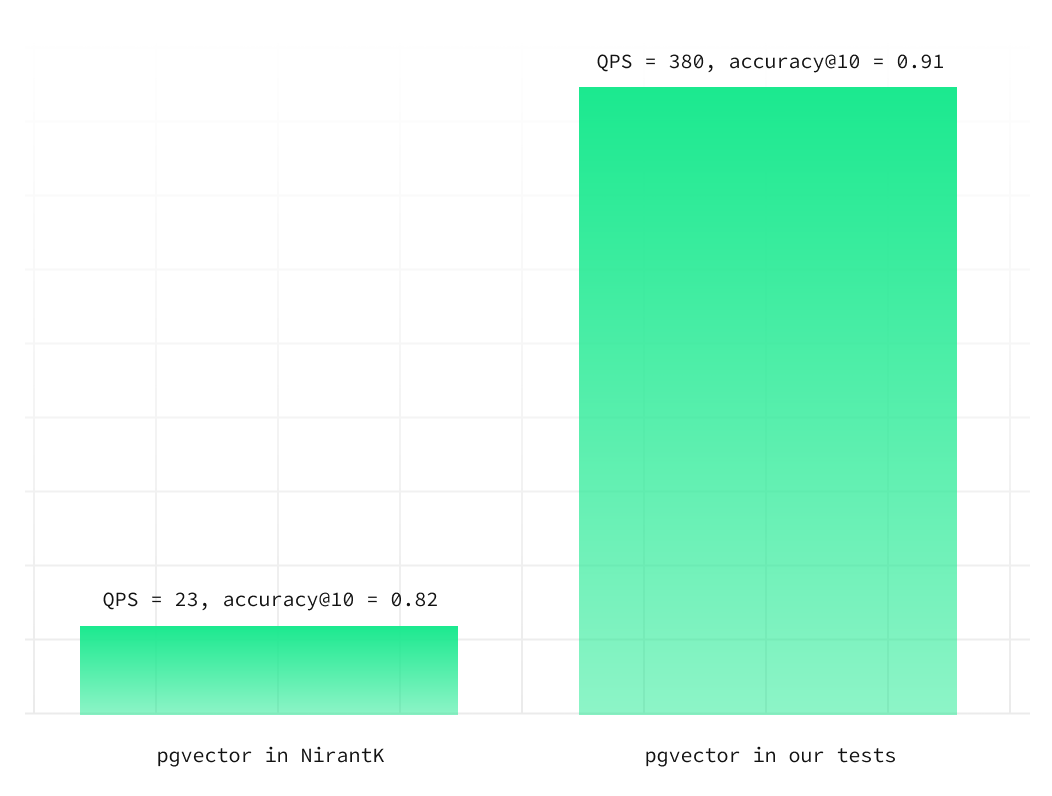
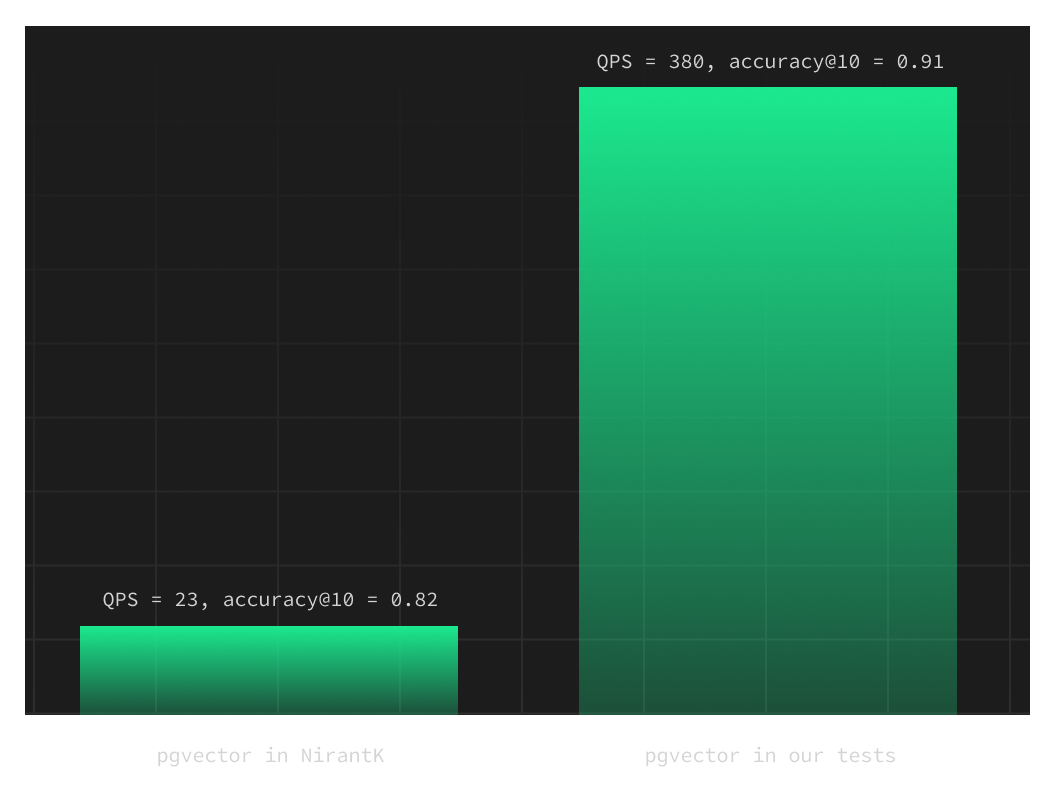
With the changes above and probes set to 10, pgvector was faster and more accurate:
- accuracy@10 of 0.91
- QPS (queries per second) of 380
PROBES = 40
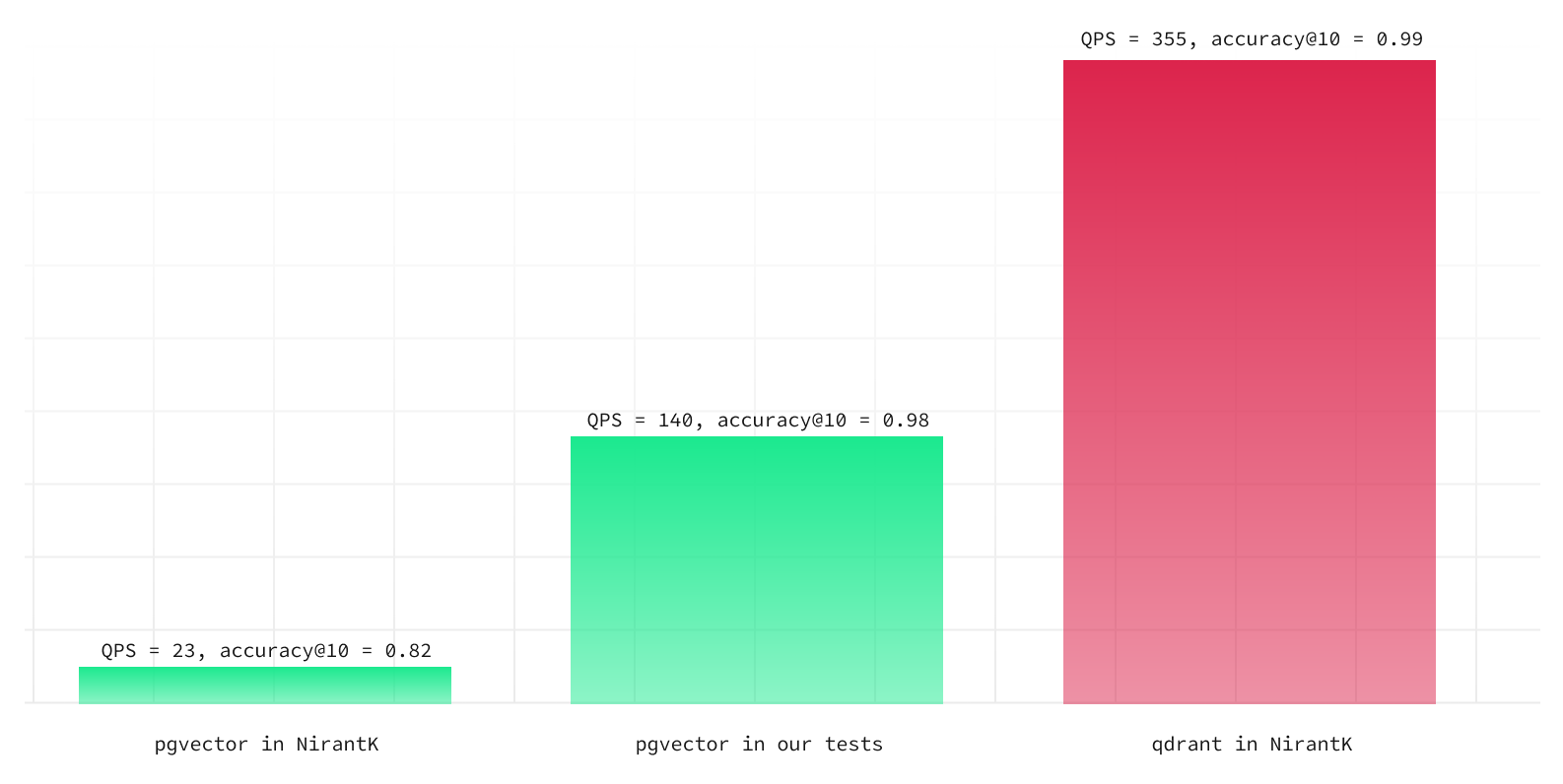
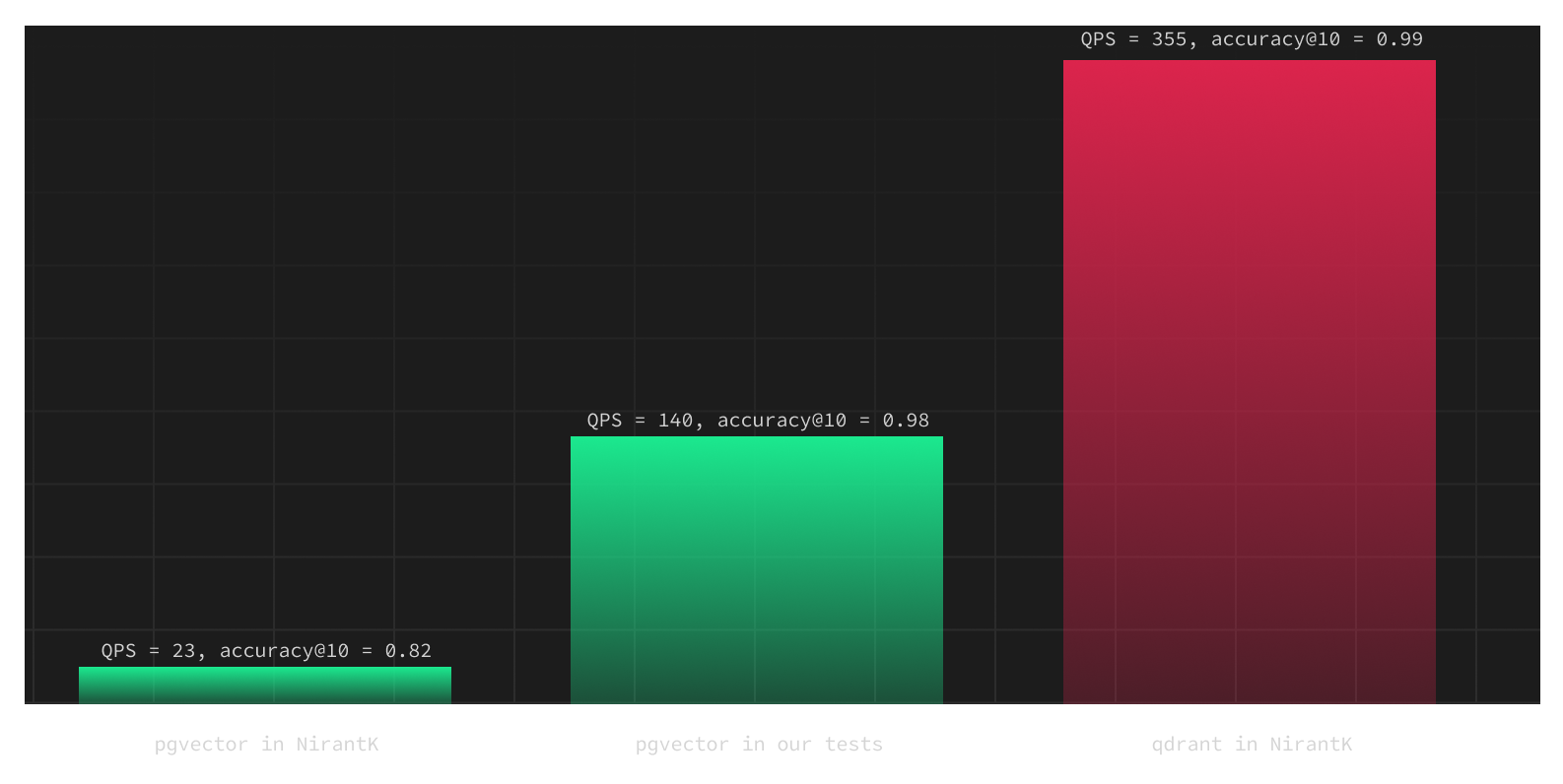
If we increase the probes from 10 to 40, pgvector was not just substantially faster but also boasted almost the same accuracy as Qdrant:
- accuracy@10 of 0.98
- QPS of 140
Scaling the database
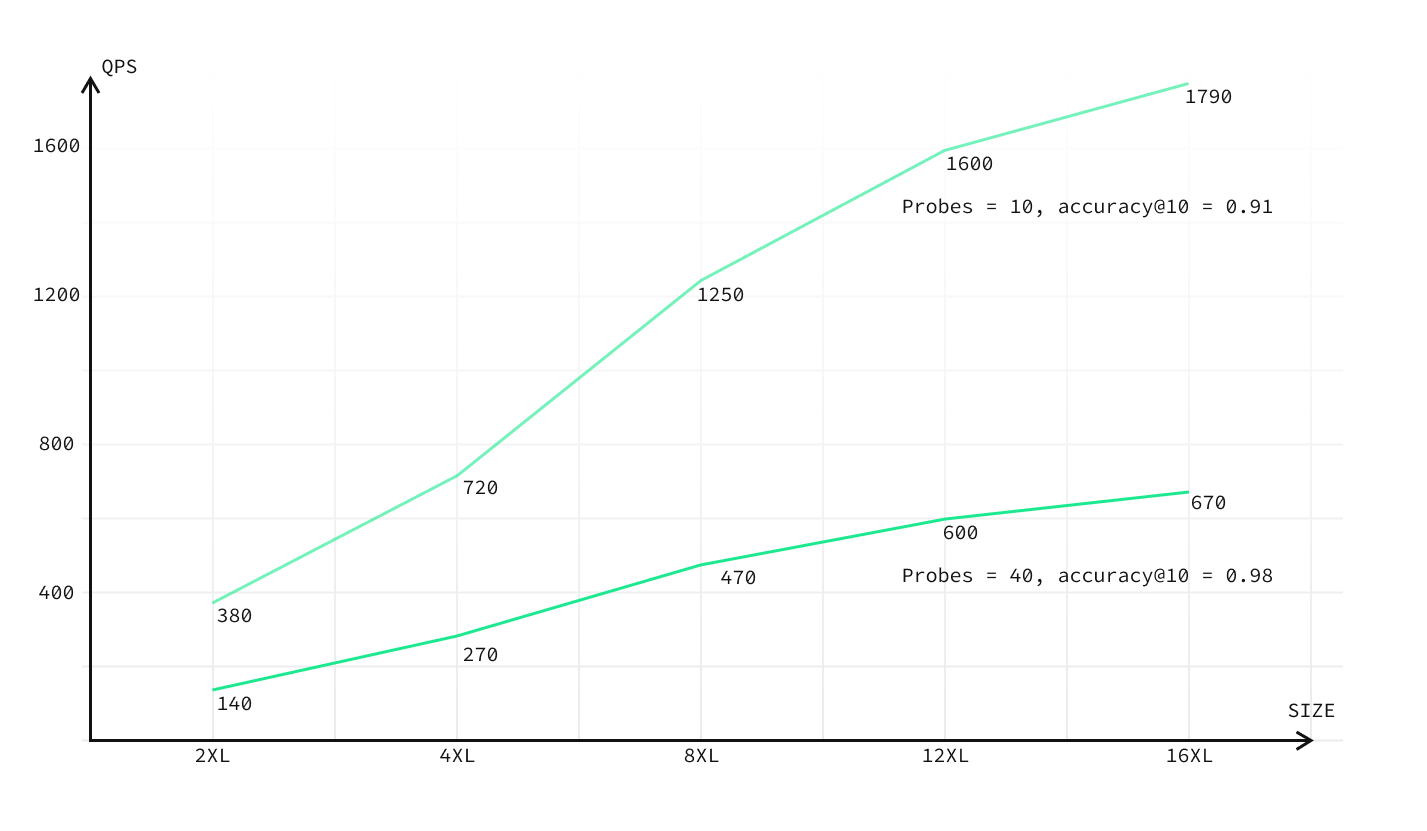
Another key takeaway is that the performance scales predictably with the size of the database. For instance, a 4XL instance achieves accuracy@10 of 0.98 and QPS of 270 with probes set to 40. Moreover, an 8XL compute add-on analogously obtains accuracy@10 of 0.98 and an QPS of 470, surpassing the results of Qdrant.
The Qdrant benchmark uses “default” configuration and is in not indicative of its capabilities after modifying the configuration.
Although more compute is required to match Qdrant's accuracy and QPS levels concurrently, this is still a satisfying outcome. It means that it's not a necessity to use another vector database. You can put everything in Postgres to lower your operational complexity.
Final results: pgvector performance
Putting it all together, we find that we can predictably scale our database to match the performance we need.
With a 64-core, 256 GB server we achieve ~1800 QPS and 0.91 accuracy. This is for pgvector 0.4.0, and we've heard that the latest version (0.4.4) already has significant improvements. We'll release those benchmarks as soon as we have them.
Other performance factors
It's been about 5 months since we added pgvector to the platform. Since then we've discovered a few other important things to keep in mind.
Increasing lists improves performance
Another way to improve performance without throwing more compute would be to increase lists.
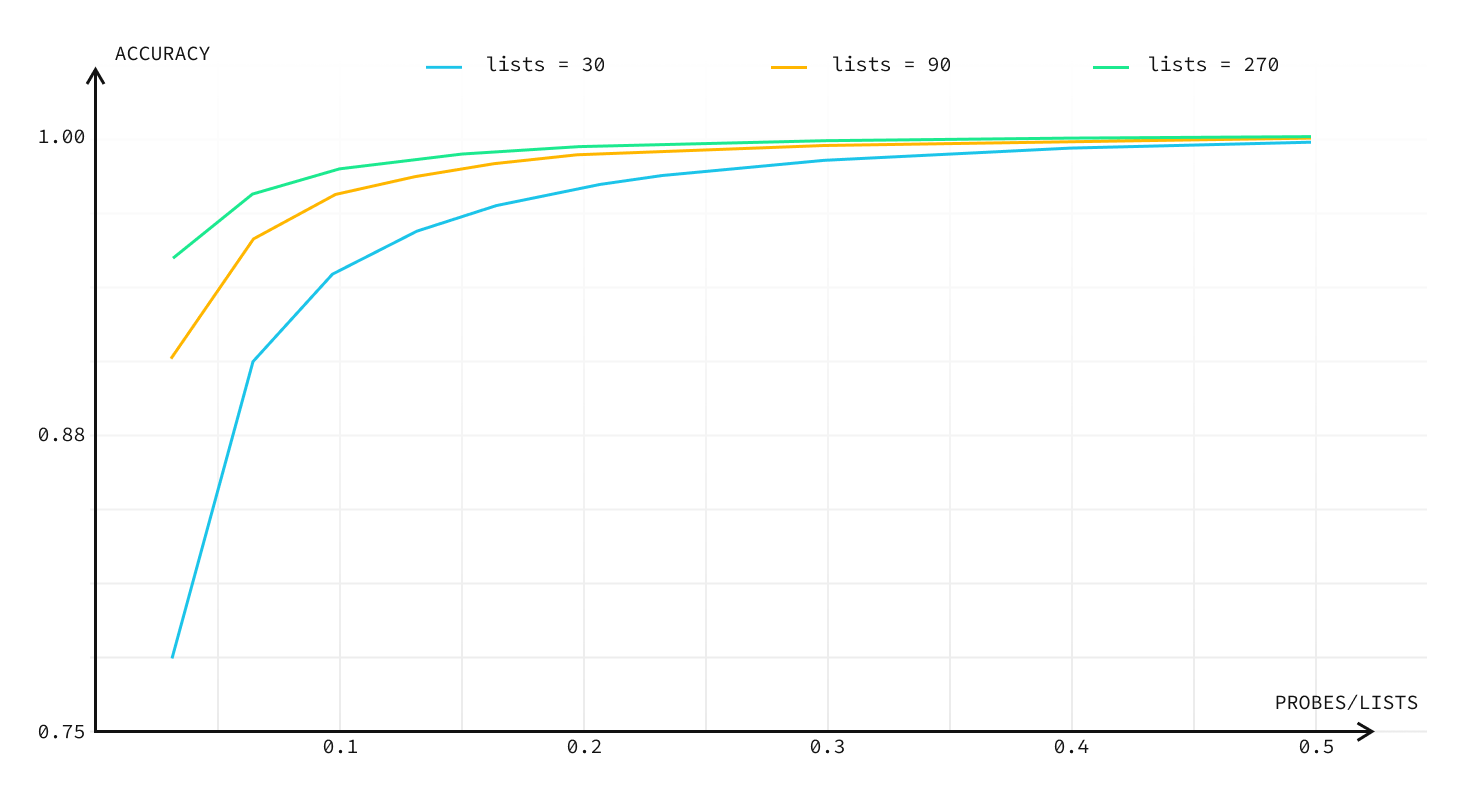
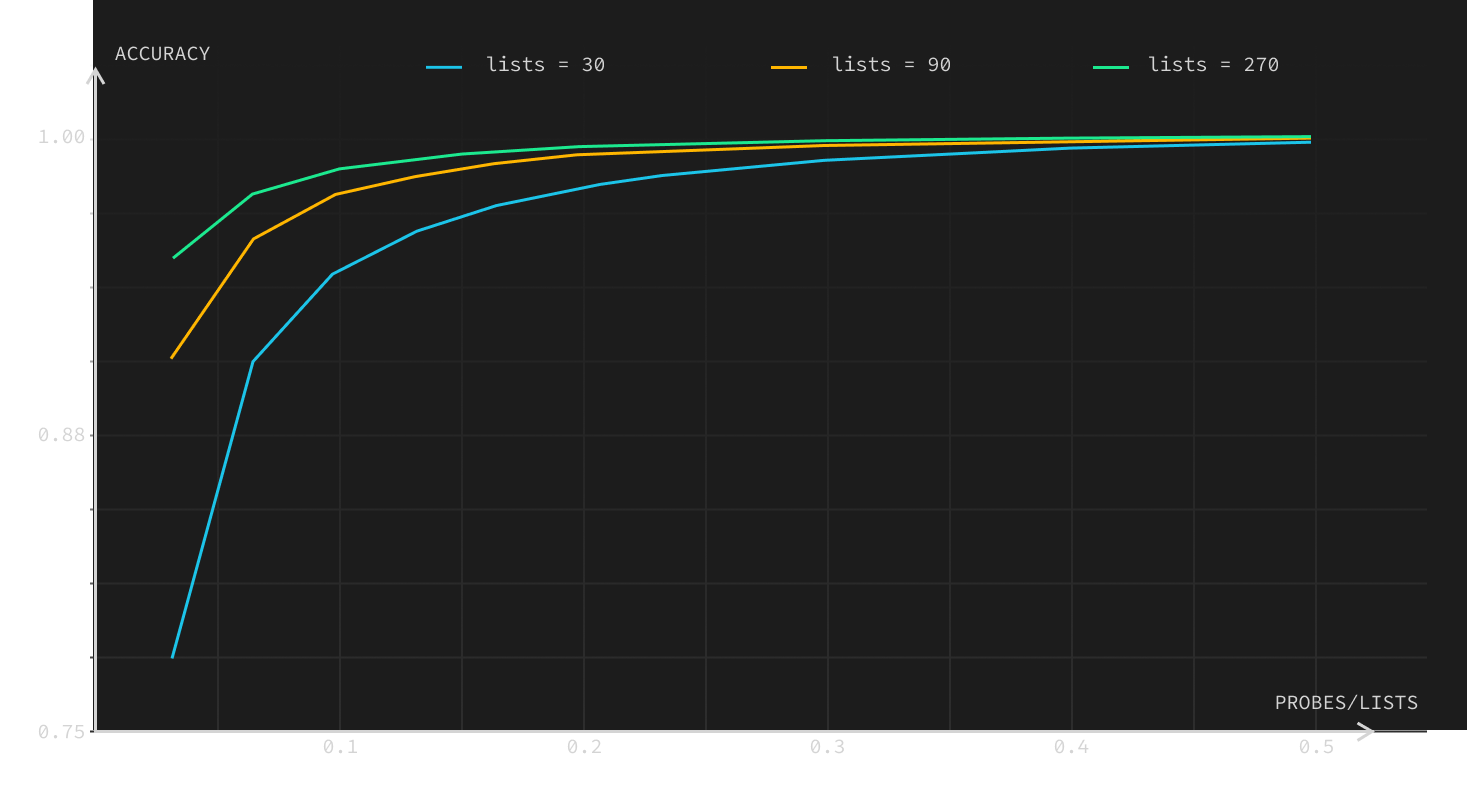
We ran a test to measure the impact of list size: we uploaded 90,000 vectors from the Wikipedia dataset and then queried 10,000 vectors from the same dataset. The documentation recommends to use lists constant of number of vectors / 1000. In this case, it would be 90.
But as our experiment shows, we can improve QPS if we increase lists (i.e. with more lists in the index we need to get less index data to get the same accuracy). So for 95% accuracy, we can take any of:
- 3% of index data = 270 lists
- 6% of index data = 90 lists
- 13% of index data = 30 lists
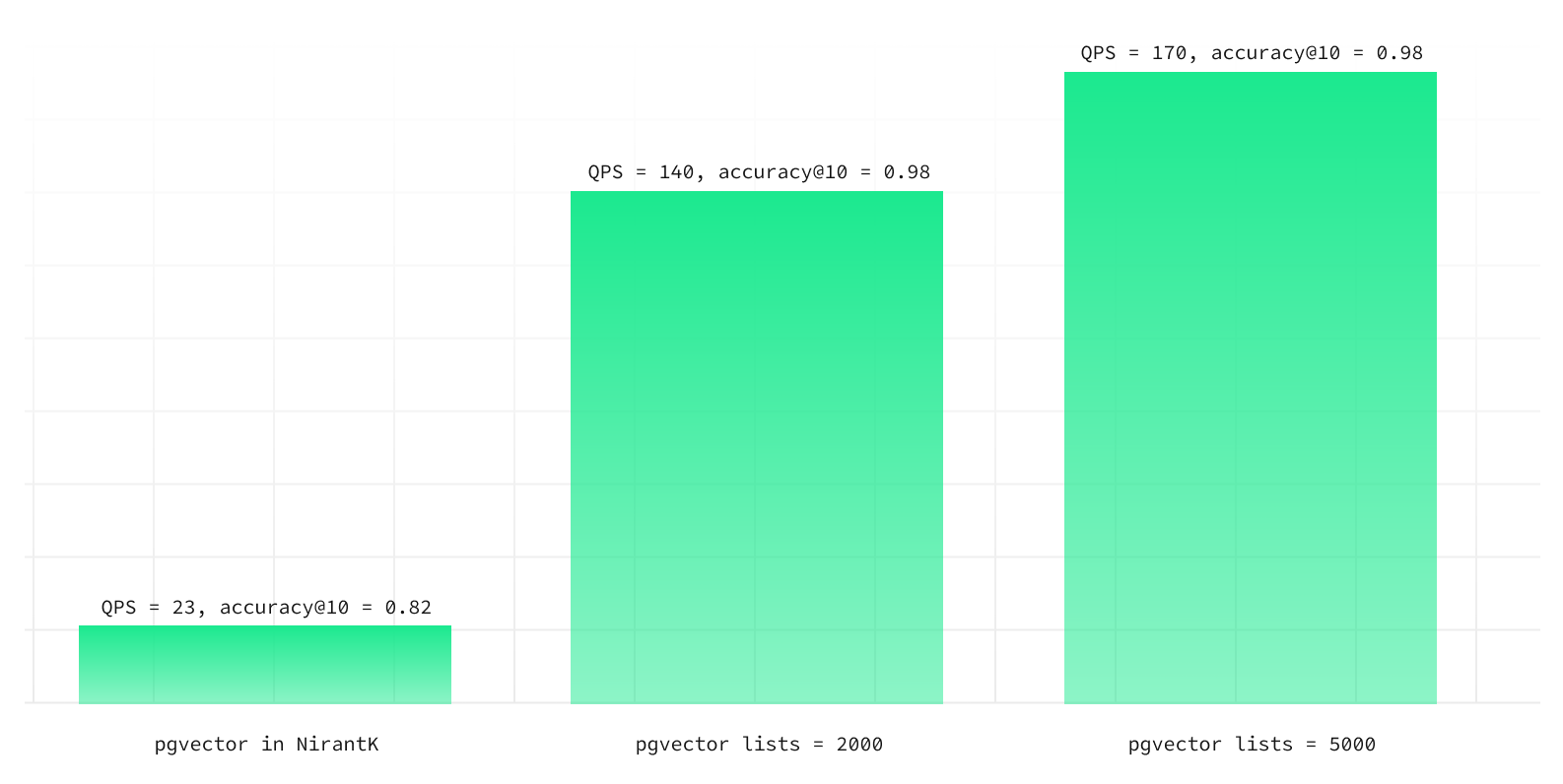
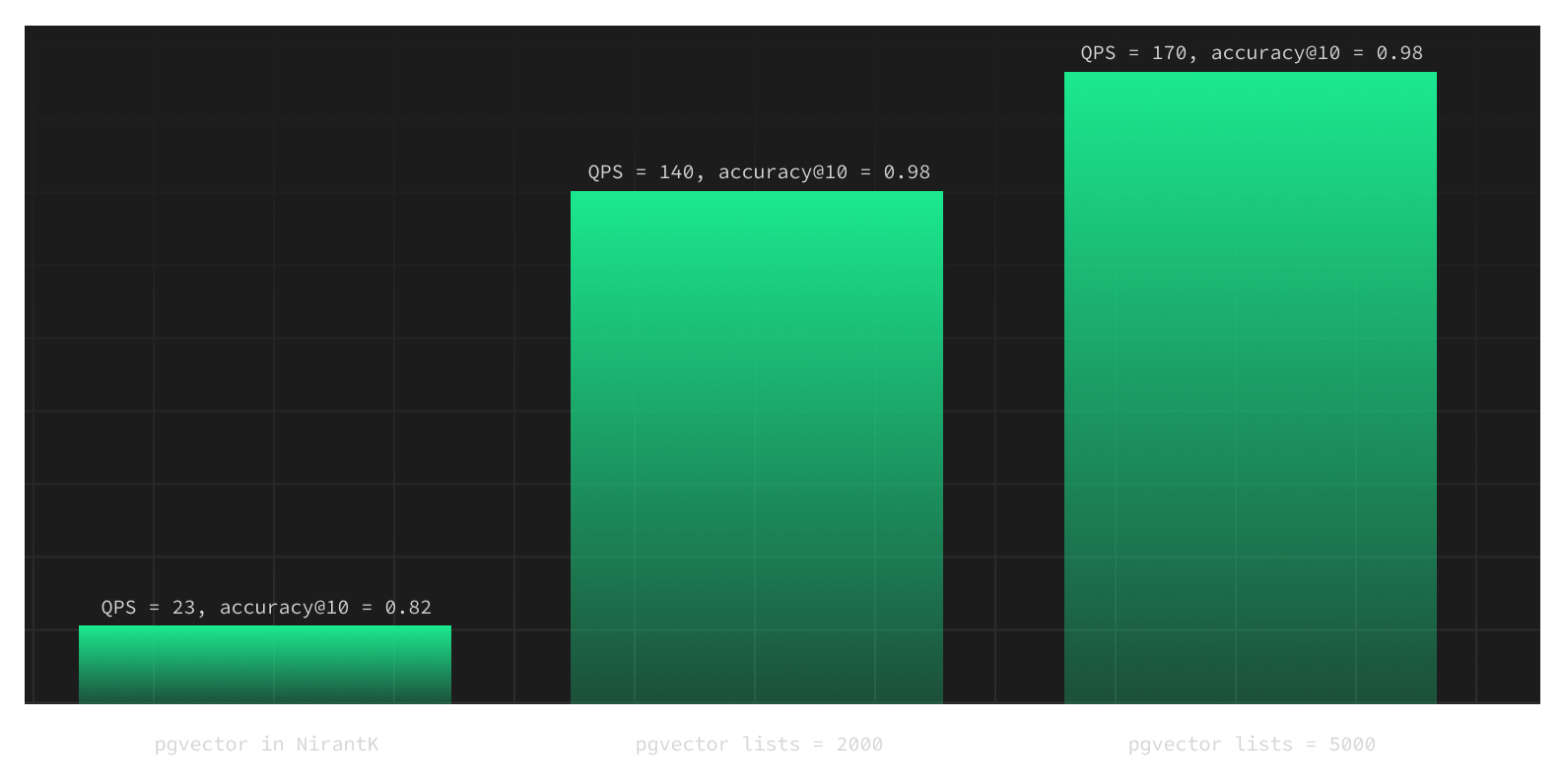
This also has an important caveat: building the index takes longer with more lists. Here we measure the index build time for a dataset containing 900,000 vectors:
So if you can afford an index build time of 1 hour or more, you can go with lists=5000 (number of vectors / 200) or more!
You may need to increase maintenance_work_mem to be able to create an index with high values for lists. For example:
_10SET maintenance_work_mem TO '7168 MB';
Keeping in mind that the overall index size is almost the same, and only index build time increases, we can say that it's better to use more lists for better select queries speed.
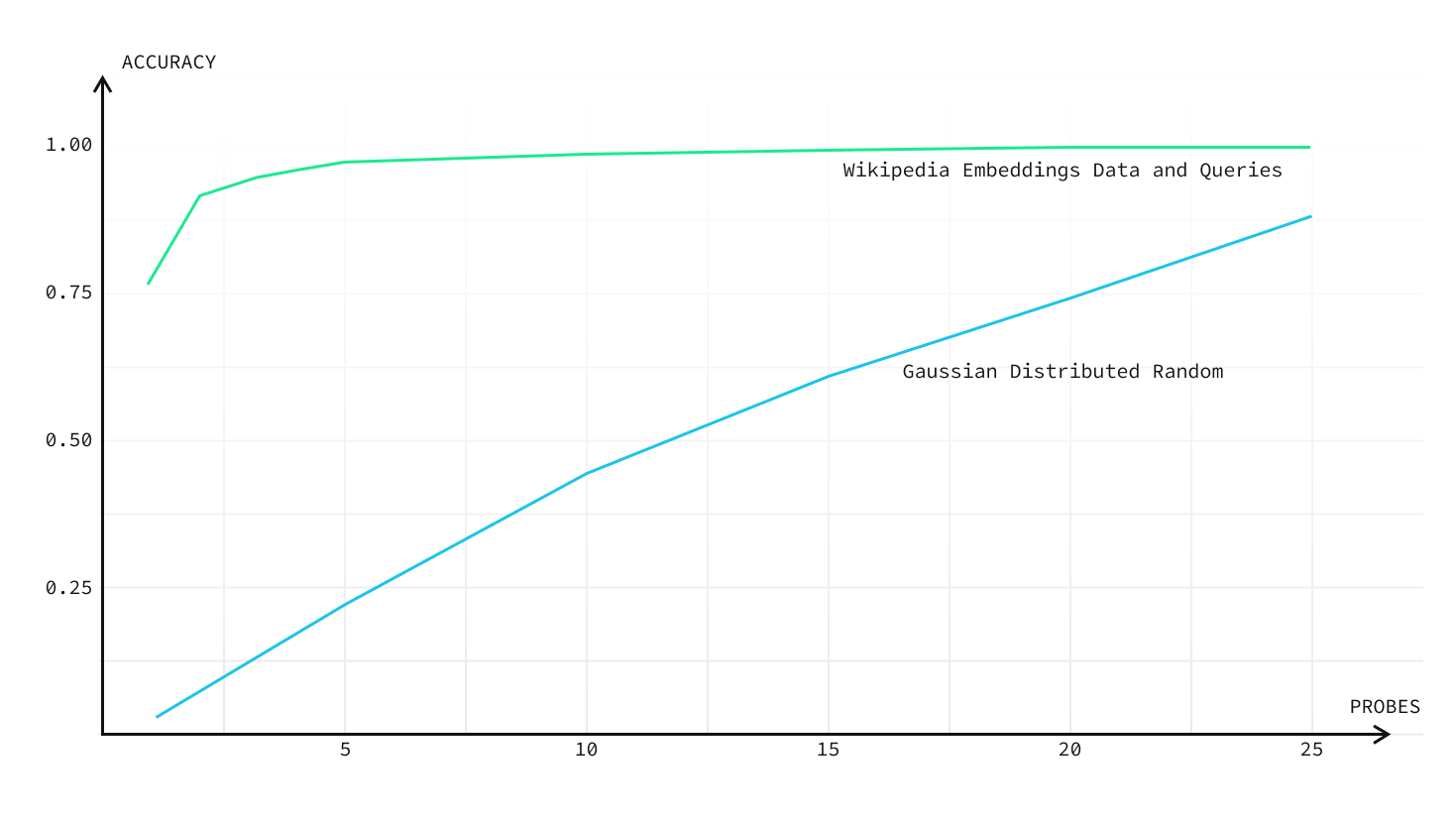
Real data has higher accuracy than random data
Embeddings created from “real” data are more likely to be clustered together, whereas random embeddings are more likely to be scattered. In other words, real embeddings are very far from being randomly distributed. This might seem obvious, but it's an important call-out for benchmarks.
Embeddings generated for similarity search using “real world data” will be more correlated, so the accuracy will be higher as well. You can see the difference in this chart using 10,000 Wikipedia embeddings, vs 10,000 randomly-generated embeddings:
Optimizing pgvector performance
Armed with all this information, we can safely give you a few tips and strategies for optimizing your pgvector workloads.
Tips
First, a few generic tips which you can pick and choose from:
- Adjust your Postgres config. It should be aligned with RAM & CPU cores. Find more details here.
- Prefer
inner-producttoL2orCosinedistances if your vectors are normalized (liketext-embedding-ada-002). If embeddings are not normalized,Cosinedistance should give the best results with an index. - Pre-warm your database. Implement the warm-up technique we described earlier before transitioning to production.
- Establish your workload. Increasing the lists constant for the pgvector index can accelerate your queries (at the expense of a slower build). For instance, for benchmarks with OpenAI embeddings, we employed a
listsconstant of 2000 (number of vectors / 500) as opposed to the suggested 1000 (number of vectors / 1000). - Benchmark your own specific workloads. Doing this during cache warm-up helps gauge the best value for the
probesconstant, balancing accuracy with QPS.
Going into production
Before running your pgvector workload in production, here are a few steps you can take to maximize performance.
- Over-provision RAM during preparation. You can scale down in step
5, but it's better to start with a larger size to get the best results for RAM requirements. (We'd recommend at least 8XL if you're using Supabase.) - Upload your data to the database. If you use
vecslibrary, it will automatically generate an index with default parameters. - Run a benchmark using randomly generated queries and see the results. Again, you can use
vecslibrary with theann-benchmarkstool. Do it with probes set to 10 (default) and then with probes set to 100 or more, so QPS will be lower than 10. - Take a look at the RAM usage, and save it as a note for yourself. You would likely want to use compute add-on in the future that would have the same amount of RAM as used at the moment (both actual RAM usage and RAM used for cache and buffers).
- Scale down your compute add-on to the one that would have the same amount of RAM as used at the moment.
- Repeat step 3. to load the data into RAM. You should see that QPS is increased on subsequent runs, and stop when it no longer increases. Then repeat the benchmark with probes set to a higher value as well if you didn't do it before on that compute add-on size.
- Run a benchmark using real queries and see the results. You can use
vecslibrary for that as well withann-benchmarkstool. Do it with probes set to 10 (default) and then gradually increase/decrease probes value until you see that both accuracy and QPS match your requirements. - If you want higher QPS and you don't expect to have frequent inserts and reindexing, you can increase
listsconstantly. You have to rebuild the index with higher lists value and repeat steps 6-7 to find the best combination oflistsandprobesconstants to achieve the best QPS and accuracy values. Higherlistsmean that index will build slower, but you can achieve better QPS and accuracy. Higher probes mean that select queries will be slower, but you can achieve better accuracy.
The pgvector roadmap
pgvector is still early in development. As with any open source tool, it needs time and resources to make it better. Supabase plans to continue supporting Andrew with his development of pgvector.
What's next on the roadmap? Andrew has an impressive list of features planned for v0.5.0:
✅ Adding HNSW: an index with better speed & accuracy than IVFFlat (at a higher memory cost)
- Product quantization: better storage for IVFFLAT, improving speed and recall
- Parallel index builds: building your IVFFLAT indexes will be much faster